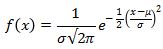Memahami Apa itu Confidence Interval
Confidence Interval mengukur tingkat ketidakpastian atau kepastian dalam metode pengambilan sampel. Mereka dapat mengambil sejumlah batas probabilitas, dengan yang paling umum adalah tingkat kepercayaan 95% atau 99%. Confidence Interval dilakukan dengan menggunakan metode statistik, seperti uji-t.
Ahli statistik menggunakan Confidence Interval untuk mengukur ketidakpastian dalam variabel sampel. Misalnya, seorang peneliti memilih sampel yang berbeda secara acak dari populasi yang sama dan menghitung Confidence Interval untuk setiap sampel untuk melihat bagaimana hal itu dapat mewakili nilai sebenarnya dari variabel populasi. Kumpulan data yang dihasilkan semuanya berbeda; beberapa interval menyertakan parameter populasi sebenarnya dan yang lainnya tidak.Confidence Interval adalah rentang nilai, dibatasi di atas dan di bawah rata-rata statistik, yang kemungkinan akan berisi parameter populasi yang tidak diketahui. Tingkat kepercayaan mengacu pada persentase probabilitas, atau kepastian, bahwa Confidence Interval akan berisi parameter populasi sebenarnya ketika Anda menggambar sampel acak berkali-kali. Atau, dalam bahasa sehari-hari, “kami 99% yakin (tingkat kepercayaan) bahwa sebagian besar sampel ini (Confidence Interval) berisi parameter populasi yang sebenarnya.”
Kesalahpahaman terbesar mengenai Confidence Interval adalah bahwa mereka mewakili persentase data dari sampel tertentu yang berada di antara batas atas dan bawah. Misalnya, seseorang mungkin secara keliru menafsirkan Confidence Interval 99% yang disebutkan di atas dari 70 hingga 78 inci sebagai menunjukkan bahwa 99% data dalam sampel acak berada di antara angka-angka ini. Ini tidak benar, meskipun ada metode analisis statistik yang terpisah untuk membuat penentuan seperti itu. Melakukannya melibatkan mengidentifikasi mean dan standar deviasi sampel dan memplot angka-angka ini pada kurva lonceng.
Menghitung Confidence Interval
Misalkan sekelompok peneliti sedang mempelajari ketinggian pemain bola basket sekolah menengah. Para peneliti mengambil sampel acak dari populasi dan menetapkan tinggi rata-rata 74 inci.
Rata-rata 74 inci adalah perkiraan titik dari rata-rata populasi. Estimasi titik dengan sendirinya memiliki kegunaan yang terbatas karena tidak mengungkapkan ketidakpastian yang terkait dengan estimasi; Anda tidak memiliki pemahaman yang baik tentang seberapa jauh rata-rata sampel 74 inci ini dari rata-rata populasi. Apa yang hilang adalah tingkat ketidakpastian dalam sampel tunggal ini.
Confidence Interval memberikan lebih banyak informasi daripada perkiraan poin. Dengan menetapkan Confidence Interval 95% menggunakan rata-rata sampel dan standar deviasi, dan dengan asumsi distribusi normal seperti yang diwakili oleh kurva lonceng, para peneliti sampai pada batas atas dan bawah yang berisi rata-rata sebenarnya 95% dari waktu.Asumsikan intervalnya antara 72 inci dan 76 inci. Jika para peneliti mengambil 100 sampel acak dari populasi pemain bola basket sekolah menengah secara keseluruhan, rata-rata harus turun antara 72 dan 76 inci di 95 sampel tersebut.
Jika para peneliti menginginkan kepercayaan yang lebih besar, mereka dapat memperluas interval hingga kepercayaan 99%. Melakukan hal itu selalu menciptakan jangkauan yang lebih luas, karena memberikan ruang untuk jumlah sampel yang lebih banyak. Jika mereka menetapkan Confidence Interval 99% sebagai antara 70 inci dan 78 inci, mereka dapat mengharapkan 99 dari 100 sampel yang dievaluasi mengandung nilai rata-rata di antara angka-angka ini.
Tingkat kepercayaan 90%, di sisi lain, menyiratkan bahwa kita mengharapkan 90% dari perkiraan interval untuk memasukkan parameter populasi, dan seterusnya.
Apa yang bisa dilakukan dengan Confidence Interval?
Confidence Interval adalah rentang nilai, dibatasi di atas dan di bawah rata-rata statistik, yang kemungkinan akan berisi parameter populasi yang tidak diketahui. Tingkat kepercayaan mengacu pada persentase probabilitas, atau kepastian, bahwa Confidence Interval akan berisi parameter populasi sebenarnya ketika Anda menggambar sampel acak berkali-kali.
Bagaimana Confidence Interval Digunakan?
Ahli statistik menggunakan Confidence Interval untuk mengukur ketidakpastian dalam variabel sampel. Misalnya, seorang peneliti memilih sampel yang berbeda secara acak dari populasi yang sama dan menghitung Confidence Interval untuk setiap sampel untuk melihat bagaimana hal itu dapat mewakili nilai sebenarnya dari variabel populasi. Kumpulan data yang dihasilkan semuanya berbeda di mana beberapa interval menyertakan parameter populasi sebenarnya dan yang lainnya tidak.
Apa Kesalahpahaman Umum Tentang Confidence Interval?
Kesalahpahaman terbesar mengenai Confidence Interval adalah bahwa mereka mewakili persentase data dari sampel tertentu yang berada di antara batas atas dan bawah. Dengan kata lain, akan salah untuk mengasumsikan bahwa Confidence Interval 99% berarti bahwa 99% data dalam sampel acak berada di antara batas-batas ini. Apa artinya sebenarnya adalah bahwa seseorang dapat 99% yakin bahwa rentang tersebut akan berisi rata-rata populasi.
Apa itu Tes-T?
Confidence Interval dilakukan dengan menggunakan metode statistik, seperti uji-t. Uji-t adalah jenis statistik inferensial yang digunakan untuk menentukan apakah ada perbedaan yang signifikan antara rata-rata dua kelompok, yang mungkin terkait dengan fitur tertentu. Menghitung uji-t membutuhkan tiga nilai data kunci. Mereka termasuk perbedaan antara nilai rata-rata dari setiap kumpulan data (disebut perbedaan rata-rata), standar deviasi setiap kelompok, dan jumlah nilai data dari setiap kelompok.